



「妥協」はプロセッサ設計に必要不可欠
誤解を恐れずに言えば、NehalemことCore i7というプロセッサは「偉大なる妥協の産物」である。「妥協」という言葉にネガティブなイメージを感じるかもしれないが、プロセッサの設計において「妥協」は常に必要になる。そしてプロセッサの歴史を紐解くと、理想を追い求めたプロセッサ(あえて例は示さないが)は往々にして悲惨な結果に陥ることが多い。それは商業的にという場合もあるし、それ以前に技術的な場合もある。昔のようにPCしか無かった時代ならばともかく、今は携帯やらデジタル家電やらがきわめて高機能・高性能化しており、ちょっとした用途なら携帯やデジタル家電でほとんど事が足りる。つまりPCに求められるのは、携帯やデジタル家電では間に合わない、高負荷あるいは多様多種な作業という事になる。つまり以前よりもCPUに求められるニーズが多様化しているという事ことだ。これを言い換えると、「特定の処理のみ高速」というCPUよりも、「どんな処理でも満遍なく高速」というCPUが重用されることになる。
ところが、この「満遍なく高速」を実現するためのさじ加減は非常に難しい。一般的な技術、つまり動作周波数を引き上げるとか、メモリアクセスを高速化するといった技術は、当然のことながら既に利用されている。スーパースケーラでの同時命令発行数を引き上げるとか、実行ユニットの数を増やすといった対策は消費電力増加とかダイサイズの肥大化といったデメリットを伴う。SSEに代表される拡張命令は、どんな種類のアプリケーションにも有効というわけではないし、拡張命令に未対応の古いアプリケーションでは効果がない。どんな場合にも効果的なアイディアは、もう残されていない。
「満遍なく高速」を実現するための技術
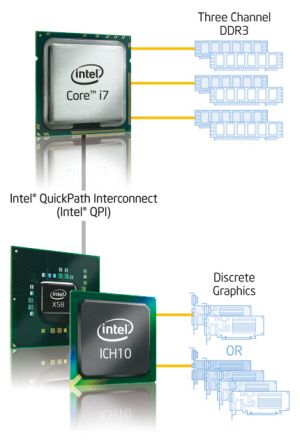
- FSBの速度でメモリアクセスが頭打ちになるボトルネックを解消
- FSB経由でメモリアクセスを行うことによるレイテンシを削減
とはいえ、サーバー用途などではまだまだ大規模キャッシュが必要である。これをカバーするのが、(より大きなレイテンシを伴うが8MBという大容量の)L3キャッシュである。ただし、エンタープライズ向けなどの用途では、8MBでもまだ足りない。これを補うのが、従来より低レイテンシで高速にアクセスできるメモリというわけだ。性能を犠牲にせず(場合によってはむしろ向上させながら)、メモリアクセス性能を効果的に引き上げる事に成功したと言える。
この場合のデメリットは、メモリの種類が特定されてしまうことだ。例えばCore 2 Duo/Quadの場合、チップセットの選択によりDDR2とDDR3の両方のメモリが選択可能だった。ところがCore i7の場合、DDR3しか選べないことになる。もっとも以前はメモリの種類が多く、チップセットを変えることで様々なメモリに対応できるようにするといった必要性があったが、最近ではメモリの種類も限られており、こうした形でメモリの種類を固定しても余り実害は無いと判断したのであろう。これはリーズナブルな妥協である。
次にCPUコアそのものだが、Core i7のCPUコアは従来のCoreマイクロアーキテクチャと原理的にほとんど変更が無い。大きな違いは
- LSD(Loop Stream Detector)を搭載
- Store Unitを2つに増強(Coreマイクロアーキテクチャは1つ)
- HyperThreadingを搭載
実のところ、条件さえ整えば、Coreマイクロアーキテクチャは十分に高速なアーキテクチャである。そこで、敢えて性能強化の方向にはあまりリソースを費やさず、むしろ弱点解消の方向にリソースを振ったところに高次元の妥協を見出すことができよう。
車のエンジンで言えば、ピーク性能はエンジン内部のフリクションを低下させて若干向上させる程度に留めておき、チューニングのメインは低回転域におけるトルクを厚くする作業に専念したといったところだ。
回路の再設計で実現した精妙な性能バランス
ではCore i7はCoreマイクロアーキテクチャの延長に過ぎないのか?というとそういうわけではない。確かにパイプライン構造などを見る限りはほとんど同じだが、回路そのものは完全に再設計が行われている。その理由は省電力機構にある。コアごとに電力のOn/Offを管理できる(これを実現するために、Intelは従来考えもしなかったような半導体の配線技術を開発した)ことと、主要な回路をStatic化するという決断により、同じ回路であれば従来よりも大きく消費電圧を下げられる技術を投入した。これによって、4コア/8スレッドのCPUコア+メモリコントローラが従来と同じ消費電力枠でより高速に動作するようになった。例えばこの消費電力削減分を高速動作に振り分ければ、5GHz超のCore 2 Duoも簡単に実現できたかもしれない。それをあえて低めに抑え、その分4コア/8スレッドを安定動作する方向に振ったあたりもまた、高次元の妥協であろう。
そんなわけで、ピーク性能だけを比較すると、おそらくCore i7の性能はそれほど高くはないだろう。ところが実際にアプリケーションを使ってみると、何をやっても「遅くならない」と感じるはずだ。カタログ値はしばしばピーク性能が利用されるから、マーケティング的には決して嬉しい方向性ではないかもしれない。にも関わらず、そうしたピーク性能ではなくアベレージの性能を引き上げる方向に開発の舵を取ったという「妥協」を、筆者は非常に好ましく感じる。
[Reported by 大原雄介]